Programmiersprachen und Übersetzer
01 - Einleitung
Inhaltsverzeichnis



- Mausklick: Im Folienstapel vorwärts gehen.
- Shift+Mausklick: Im Folienstapel rückwärts gehen.
1 Einleitung
In diesem Skript sind die Themen der Vorlesung "Programmiersprachen und Übersetzer" noch einmal schriftlich erörtert. Dabei erhebt das Skript keinen Anspruch auf Vollständigkeit und es ersetzt auch nicht die Lektüre von Lehr- und Fachbüchern. Im Verlaufe der Veranstaltung werden Sie entsprechende Literaturhinweise, sowohl Bücher als auch Links zu entsprechenden Fachartikeln und Blogeinträgen, finden. Sollten Sie weitere interessante Artikel zur Veranstaltung finden, scheuen Sie sich nicht, mir diese zuzusenden.
Um unnötige Dopplungen mit den Folien zu vermeiden, haben wir die einzelnen Vorlesungsfolien in dieses Dokument mit eingebunden. Zu den jeweiligen Abschnitten finden Sie die Erläuterungen, Ergänzungen und Informationen, die während der Vorlesung auf der "Tonspur" erzählt werden. In den jeweiligen Folienblöcken können Sie mittels Mausklick vorwärts, und bei gedrückter Shifttaste rückwärts, navigieren.









Zunächst stellt sich die Frage, wieso es für einen Informatiker sinnvoll ist, sich im Detail mit Programmiersprachen, ihren Konzepten und ihrer Übersetzung in Maschinencode zu beschäftigen. Schließlich gibt es all diese Werkzeuge bereits und wir können sie einfach verwenden. Außerdem haben Sie vielleicht das Gefühl, dass Übersetzer und deren Konstruktion ein schwierig zu durchdringendes Thema sind und eher an schwarze Magie denn an normale Programmierung erinnern. Aus eigener Erfahrung kann ich Ihnen sagen: Dem ist nicht so und sowohl Programmiersprachen, als auch Übersetzer, sind ein spannendes Feld der Informatik, in dem eine beständige Entwicklung stattfindet.
Diese beständige Entwicklung stellt allerdings auch eine Herausforderung für Sie, als Informatiker oder Informatik-geneigter Ingenieur, dar. Mit den Programmiersprachen, die Sie im Laufe Ihres Studiums konfrontiert sind, werden Sie nicht über die nächsten 40 Jahre kommen. Um zukunftssicher zu werden, brauchen Sie nicht nur rein technisches Wissen über eine oder zwei Sprachen, sondern systematisches und konzeptionelles Wissen, das nicht so schnell altert, wie der Hype-Train vom Java Bahnhof, über die C# Hochebene, zur Rust-Mine braucht.
Aber nicht nur die fortschreitende Entwicklung einzelner Programmiersprachen oder das Aufkommen von ganz neuen Sprachen bringt dauerhafte Relevanz für das Thema, sondern auch die schiere Prävalenz und die Vielfalt an Sprachen, die von Computern mechanisch verarbeitet werden. Sprachen werden nicht nur für die Kodifikation von ausführbaren Programmen verwendet, sondern, unter anderem, auch zur Aufbereitung von Informationen (z.B. HTML5 oder TiKZ) oder zur Beschreibung von Datenabfragen (z.B. SQL oder Overpass).
Im Laufe Ihres Lebens wird, nachdem in ihrem Projekt entschieden wurde die Programmiersprache R++ in Version 2034 zu verwenden, die Anforderung an Sie gestellt werden, möglichst schnell effektiv darin zu werden ein möglichst effizientes Programm zu schreiben. Die von Ihnen erwartete Effektivität besteht darin, dass Sie die Fähigkeit erarbeiten, überhaupt ein Programm zu schreiben. Die erwartete Effizienz besteht darin, dass das erstellte Programm nicht unrealistisch lange für eine einfache Aufgabe braucht. Aber auch, wenn Sie selbst in die Lage kommen, die Wahl der Programmiersprache für ein neues Projekt zu treffen, brauchen Sie das nötige Wissen, um eine informierte Entscheidung treffen zu können. Beispielsweise muss die Abwägung zwischen der performanten Ausführung einer übersetzten Sprache und der schnellen Entwicklung in einer Skriptsprache, je nach Anwendungsfall, Unternehmenstruktur und Verfügbarkeit von Entwicklern, anders getroffen werden. Ein Startup, welches seine Webanwendung in COBOL entwickelt, wird es schwer haben die nötige Entwicklungsgeschwindigkeit zu erreichen.
Da Sie das Erlernen neuer Sprachen also nicht vermeiden können, können Sie es sich auch gleich möglichst einfach machen und wiederverwendbare Konzepte lernen anstatt 20 Ausprägungen von selbem Konzept. Dies ist auch das angepeilte Vorgehen dieser Veranstaltung: Wir werden uns Sprachkonzepte anschauen, die immer wieder auftauchen, und wir werden versuchen ihre Essenz herauszudestillieren. Dabei werden wir uns Beispiele aus verschiedensten Sprachen anschauen, um unterschiedliche Ausprägungen dieser Konzepte kennenzulernen. Nur so können wir der großen Vielfalt an Sprachen adäquat begegnen, ohne in einer Flut technischer Details unterzugehen.
Zu Gute kommt uns dabei, dass Ingenieure, auch bei der Entwicklung einer neuen Sprache, nicht jedes mal auf der grünen Wiese anfangen, sondern gerne auf altbewährte Konzepte zurückgreifen. Diese evolutionäre Entwicklung ist allerdings nicht reiner Phantasielosigkeit geschuldet, sondern hat den sozialen Faktor, dass andere Ingenieure einfacher in die neue Sprache hineinfinden; die Einstiegshürde ist deutlich geringer. Ein Beispiel für das evolutionäre einschleichen eines Sprachkonzepts in den Kanon allgemein bekannter Konzepte ist die Iteration über eine Sequenz von Elementen. Wo in C noch umständlich mit Zeigern hantiert wird, und die ursprüngliche C++-Variante beinahe genauso aussieht, hat die aktuelle Version von C++ die Möglichkeit, mittels einer Kurzschreibweise, über Sequenzen zu iterieren.
sequence = [1, 1, 2, 3, 5, 8, 13] idx = 0 while idx < len(sequence): print(sequence[idx]) idx += 1 print("---") for element in sequence: print(element)
Im Verlaufe des Skriptes gibt es Quellcodebeispiele, die direkt im Browser ausgeführt werden können. Um die Ladezeit der Seite zu verringern, haben wir darauf verzichtet diese Funktionalität standardmäßig zu aktivieren. Durch einen Klick auf den "Load Interpreter" Button, wird Klipse nachgeladen und die Beispiele erwachen zum Leben und können auch direkt im Browser editiert werden. Allerdings erfolgt das Nachladen von Klipse von Drittseiten, auf deren Einstellung zu Ihrer Privatsphäre wir keinen Einfluss haben. Falls Sie Browserplugins zur digitalen Selbstverteidigung, wie uMatrix, nutzen, müssen Sie Ihre Einstellungen entsprechend anpassen. Ansonsten können Sie den Codeschnipsel auch herauskopieren und als Python (leider nur Version 2) Programm ausführen
2 Inhalt der Veranstaltung


Diese Veranstaltung trägt den Namen "Programmiersprachen und Übersetzer" und ist dementsprechend auch entlang dieser beiden Begriffe in zwei Teile getrennt, die allerdings eng miteinander interagieren. Die Programmiersprachen geben vor, welche Konstrukte bei der effektiven Kodierung von Programmen verwendet werden können. Auf der Gegenseite entscheidet der Übersetzer, wie diese Konstrukte auf die darunterliegende Maschine abgebildet werden und bestimmt damit maßgeblich die Effizienz der Programmausführung.
Im Bereich der Sprachen werden wir uns mit Kernkonzepten beschäftigen, die in vielen unterschiedlichen Sprachen auftauchen.
Dazu gehört die Frage nach Typannotationen (z.B. int, struct element), genauso wie die Menge der verwendbaren Kontrollstrukturen (z.B.
if, while, do-while).
Hierbei werden wir einen Fokus auf jene Konzepte werfen, die in Sprachen verwendet werden, die dem funktionalen bzw.
dem objektorientierten Paradigma zugeordnet werden können.
Man kann davon sprechen, dass ein Programmierparadigma aus diesen Konzepten zusammengesetzt wird, um einen bestimmen Stil oder eine "Philosophie" von Implementierungen zu ermöglichen.
Jedoch kann heute kaum noch eine Programmiersprache nur einem dieser Paradigmen zugeordnet werden.
Auf Seite der Übersetzer wollen wir uns jene Zwischenschritte anschauen, die notwendig sind, um Programme einer Hochsprache in die eigentliche Sprache der Maschine zu übersetzen. Durch diese mechanische Übersetzung, bei der die Abstraktionen der Sprache schrittweise abgebaut werden, können wir nicht nur feststellen, ob bei der Kodierung Fehler passiert sind (der Übersetzung schlägt fehl), sondern es können auch diverse Optimierungen durchgeführt werden, auf die wir ebenfalls einen kurzen Blick werfen wollen. Dabei können die Vorlesungseinheiten zum Übersetzerbau kein vollständiges Bild liefern, dazu ist die Vielfalt an möglichen Sprachkonstrukten zu groß. Das Ziel dieser Termine ist es, Ihnen einen Überblick über die kanonischen Zwischenschritte der Übersetzung von imperativen Sprachen zu geben. Dabei ist es ebenfalls mein Ziel, Ihnen eine Intuition zu vermitteln, welche Konstrukte einer Sprache inhärent weniger effizient sind als andere.
Als Literatur zu dieser Vorlesung empfehle ich ihnen "Programming Language Pragmatics" von Michael L. Scott, welches eine ähnliche Mischung von Sprachkonzepten und Übersetzerbau wie diese Vorlesung hat. Dabei deckt dieses Buch viel mehr ab als wir in dieser Veranstaltung machen können, und ist daher nicht nur eine gute Grundlage zur Vor- und Nachbereitung, sondern auch ein Startpunkt für alle Studierenden, die sich noch tiefer mit dem Thema auseinandersetzen wollen. Daneben muss man auch das klassische Buch zum Übersetzerbau von Ullmann, Lam, Sethi und Aho empfehlen, welches den Übersetzerbau noch intensiver diskutiert. Im Laufe der Veranstaltung werde ich, wo sinnvoll, einzelne Unterkapitel aus diesen Büchern referenzieren.







Die drei Themenbereiche Übersetzertechniken, Sprachkonzepte und Paradigmen von Programmiersprachen werden in den nächsten 12 Vorlesungen vermischt und aufeinander aufbauend behandelt. Dabei werden wir in der ersten Hälfte des Semesters die notwendigen Grundlagen an Sprachkonzepten schaffen, um diese dann direkt in der entsprechenden Phase der Übersetzung verwenden zu können. Zum Beispiel führt die semantische Analyse sowohl die Typprüfung als auch die Namensauflösung durch, wodurch Vorlesung 2 und 3 direkt in die Semantische Analyse im Übersetzer übergehen.
In der zweiten Hälfte des Semesters wird der Fokus der Veranstaltung sich in beide Richtungen erweitern: Zum einen lernen wir die weiteren technischen Schritte kennen, um vom abstrakten Syntaxbaum zum fertigen Maschinenprogramm zu kommen. Zum anderen schauen wir uns die Philosophie hinter dem objektorientierten und dem funktionalen Programmierparadigma an, welche aus den grundlegenden Sprachkonzepten komponiert sind. Hier geht es nur noch teilweise um konkrete Techniken und Sprachkonstrukte, sondern mehr um jene Designentscheidungen und Prinzipien, die man anwenden muss, um objektorientiert bzw. funktional zu programmieren. Denn nur weil eine Sprache Abstraktionen für Klassen und Objekte anbietet, heißt es noch lange nicht, dass alle Programme, die in jener Sprache verfasst sind, automatisch auch objektorientiert sind. Man kann jede Turing-vollständige Sprache gegen den Strich bürsten; man sollte es nur nicht tun.
Die einzelnen Schritte der Übersetzung können wir in mindestens vier Abschnitte einteilen, die von weiteren, optionalen, Abschnitten begleitet werden können. Jeder dieser Abschnitte wird in einer Vorlesung behandelt und soll einen Überblick über das jeweilige Thema bieten.
- Syntaktische Analyse
- Die Übersetzung startet in der syntaktischen Analyse mit dem Einlesen des Programms als Zeichenkette (z.B. von der Festplatte). Dabei haben die einzelnen Zeichen noch keinerlei Bedeutung (oder Semantik) für den Übersetzer, sondern es ist nur ein Array von Bytes. Zu diesem Zeitpunkt ist der Quellcode noch nach dem jeweiligen Gusto des Programmierers (z.B. überflüssige Leerzeichen) formatiert. Durch die syntaktische Analyse überführen wir diese Sequenz von Bytes in einen abstrakten Syntaxbaum (AST), der die hierarchische Programmstruktur widerspiegelt. In dem gezeigten Beispiel, ist die Bedingung
a > bals erstes Kind der Bedingung im Baum eingeordnet. Um diesen Schritt der Strukturextraktion zu machen, werden wir uns die Lexing (Abtastung) und Parsing (Zerteilung) anschauen. Nachdem wir ein Programm syntaktisch analysiert haben, wissen wir, ob es einen Syntaxfehler enthält. Allerdings ist noch nicht klar, ob es wirklich ein valides Programm der gewünschten Sprache ist, denn es könnte zum Beispiel noch Typfehler enthalten. - Semantische Analyse
- Den zweiten notwendigen Schritt der Programmanalyse führen wir auf dem AST durch. Dabei analysieren wir den AST auf seine semantische Bedeutung. Zum einen bedeutet das den Schritt vom Bezeichner zum Namen (was ist die Bedeutung eines Variablennamens) zu machen und für jede Verwendung einer Variable die gültige Definition zu finden. Im Beispiel sieht man dem AST erst nach der semantischen Analyse an, dass
aeine lokale undbeine globale Variable ist. Weiterhin wird das Programm auf Typkorrektheit hin untersucht: Passen die von den Blättern des Baumes (unten) zur Wurzel (oben) hin propagierten Datentypen zu den verwendeten Operationen? Würde man im Beispiel schreiben23 > "hallo", wäre dies zwar syntaktisch Korrekt, jedoch nicht semantisch, da man Zahlen nicht mit Zeichenketten vergleichen darf. Nach der semantischen Analyse wissen wir endgültig, ob das Programm ein valides Programm ist. Tritt bis hier kein Fehler bei der Übersetzung auf, darf auch in den nachfolgenden Schritten kein Fehler mehr auftreten. - Erzeugung des Zwischencodes
Mit dem Übergang vom AST zum Zwischencode (engl. intermediate representation, IR) klopfen wir die hierarchische Baumstruktur einzelner Operationen platt und machen einen großen Schritt hin zur realen Maschine. Der Zwischencode moderner Übersetzer ist an Assemblerbefehle angelehnt, enthält aber noch genug Informationen, um weitreichende Programmoptimierungen durchzuführen. Der Zwischencode enthält keine sprachspezifischen Konstrukte mehr und kann daher für Sprachfrontends verwendet werden. Zum Beispiel wird sowohl die Programmiersprache Rust als auch C++ (bei Verwendung von clang) in LLVM-IREinen kurzen Überblick über LLVM-IR bietet der folgende Blogeintrag: https://idea.popcount.org/2013-07-24-ir-is-better-than-assembly/ übersetzt, bevor es an die Optimierung und Erzeugung der Binärdatei geht.
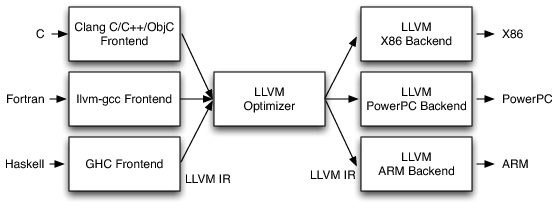
Abbildung 1: Mehrere Frontends übersetzen in die gleiche Zwischensprache und erlauben es daher den selben Optimierer und verschiedene Maschinenbackends zu verwenden. Die Abbildung stammt aus dem AOSA Buch, CC BY-SA 3.0, Chris Lattner.
- Maschinencode
- Für den letzten Schritt zur Binärdatei muss der Zwischencode zu Assemblerinstruktionen übersetzt werden. Dabei müssen semantisch äquivalente Befehle oder Befehlssequenzen der realen Maschine ausgewählt werden. Weiterhin verwendet der Zwischencode noch (unendlich viele) Variablen, wo die reale Maschine nur eine endliche Anzahl an Registern anbietet. Daher müssen die Werte an diese realen Register gebunden werden (Registerallokation).

Während wir in der Vorlesung die theoretischen Grundlagen kennenlernen, soll Ihr Wissen in der Übung weiter vertieft werden. Dies wird zum einen dadurch geschehen, dass wir Ihnen passende theoretische Aufgaben zur Bearbeitung stellen. Zum anderen sollen Sie auch praktische Übungen an einem Beispielübersetzer, der von uns bereitgestellt wird, durchführen. Dieser Übersetzer verarbeitet bereits die rudimentäre L0-Sprache und wird von Ihnen um diverse Fähigkeiten erweitert werden. Durch diese Arbeit an einem existierenden Übersetzer lernen Sie den Aufbau eines solchen Softwareprojekts kennen und können die Arbeit eines Übersetzers "live und in Farbe" erleben.
3 Organisation der Veranstaltung




4 Ebenenmodell und Virtuelle Maschinen




Nach der vorangegangenen Motivation, wieso es sich lohnt sich mit Übersetzern und Programmiersprachen zu beschäftigen, wollen wir nun diese beiden Themen in den Kanon der Informatik, genauer gesagt der systemnahen Informatik, einordnen. Hierbei sind Programmiersprachen ein ganz essenzieller Teil bei einem der grundlegendsten Problemen der Informatik: Dem Zwiespalt zwischen dem Wunsch seine Problemlösung möglichst abstrakt und nahe am Problem zu formulieren, und der Realität der real existierenden Maschinen. Diesen Zwiespalt nennen wir auch semantische Lücke, da zwischen einer mathematischen Formulierung und dem existierenden Silizium eine große Lücke klafft. Dank Alan Turing und Alonzo Church wissen wir, dass sehr einfache Turingmaschinen bereits alles berechnen können, was berechnet werden kann; aber bequem geht es dabei keinesfalls zu.
Daher ist es ein Ziel der Informatik, die man auch als die Wissenschaft von der Abstraktion bezeichnen kann, diese semantische Lücke durch möglichst gute und effiziente Abstraktionen zu schließen. Da der Abstand zwischen beiden Seiten, mathematisches Problem und reale Hardware, sehr groß ist, sind sogar mehrere Abstraktionsstufen notwendig, die als Hierarchie von virtuellen Maschinen übereinander angeordnet werden. In dieser Veranstaltung werden wir uns einer dieser Schichten, der Hochsprachenebene, von zwei Seiten, einmal von unten nach oben (Bottom-Up), und einmal von oben nach unten (Top-Down) nähern.
Durch die Hierarchie der virtuellen Maschinen, wie sie von Tanenbaum beschrieben wird, abstrahieren wir von der realen Maschine, die ganz unten liegt, schrittweise, indem wir immer abstraktere virtuelle Maschinen darüber legen. Jede dieser virtuellen Maschinen kommt mit ihrer eigenen Sprache, in der sie programmiert wird: Wo die reale Maschine mittels Binärcode programmiert wird, können wir die weiter oben liegenden Maschinen bereits in textuell erfassbarem Assemblercode oder in einer Hochsprache wie C programmieren. Die Abbildung von den oben liegenden Maschinen, die ja nicht real existieren, sondern nur rein virtuelle Konzepte sind, auf die unteren Schichten erfolgt ebenso schrittweise, wie wir die Abstraktionen aufeinander aufgetürmt haben. Dabei kann die Abbildung auf die darunterliegende Maschine entweder statisch durch eine Übersetzung oder dynamisch durch Interpretation erfolgen.Die Unterscheidung zwischen statisch (vor der Laufzeit) und dynamisch (zur Laufzeit) wird uns durch das ganze Semester hindurch begleiten. Es ist das erste Kernkonzept von Programmiersprachen, dem wir begegnen; man kann es als die Frage "Was passiert in einer Sprache statisch und was passiert dynamisch?" formulieren.
Im konkreten Falle eines Arbeitsplatzrechners ordnet sich die Hochsprachenebene direkt über der Ebene der Assemblersprache ein.
Das in den Folien gezeigte Bild kennen Sie bereits aus der Veranstaltung "Grundlagen der Betriebssysteme", in der Sie sich mit der Maschinenprogramm- und Befehlssatzebene auseinandergesetzt haben.
Zur Erinnerung:
Das Betriebssystem nimmt eine Teilinterpretation des Anwenderprogamms vor, indem es jeden Systemaufruf (int 0x80, sysenter) aus dem Maschinenprogramm interpretiert; alle anderen Befehle (mov, add) werden direkt auf der Befehlssatzebene ausgeführt.
In PSÜ werden wir uns nicht mit (Teil)Interpretation auseinandersetzen, sondern mit der Übersetzung von Hochsprachenprogrammen in Assemblersprachenprogrammen.
Dabei werfen wir auch noch kurzen Blick auf den nachgelagerten Schritt der Linkens, der neben dem Assemblieren, die letzten Schritte zum ausführbaren Binärprogramm fehlt.






Zunächst wollen wir uns mit dem Konzept der "virtuellen Maschinen", welche wir im Ebenenmodell aufeinander stapeln, genauer beschäftigen und die Frage beantworten, was diese virtuellen Maschinen sind. Dabei beschäftigen wir uns nicht mit der Virtualisierung von echter Hardware, wie bei VMWare, bei der es darum geht eine existierende Maschinenschnittstelle (der IBM PC) so zu virtualisieren, dass man mehrere Instanzen davon nebeneinander laufen lassen kann. Unsere virtuellen Maschinen haben Schnittstellen, die unterschiedlich von den Maschinen auf denen sie implementiert werden, sind.
Grundlegend besteht eine virtuelle Maschine aus zwei Komponenten: dem Speicher und den angebotenen Befehlen. Dabei können Befehle Daten aus dem Speicher lesen, sie verarbeiten, und die Ergebnisse wieder zurückschreiben. Die Gesamtheit des Speichers zu einem Zeitpunkt ist der Zustand der virtuellen Maschine. Reihen wir mehrere (valide) Befehle hintereinander, so erhalten haben wir ein Programm der Maschine. Um dieses sehr abstrakte Konzept zu verdeutlichen, wollen wir einen Prozessor für das Modell einer kleinen virtuellen Maschine in Python implementieren.
def prozessor(memory, program, maximal_steps=10): """Prozessor fuer eine virtuelle Maschine mit 2 Befehlen: inc und print""" # Der Programmzaehler zeigt den naechsten Befehl an pc = 0 steps = 0 while steps < maximal_steps and pc < len(program): steps += 1 # Der Array Zugriff: Holen der Instruktion (operation, operand) = program[pc] # Das if: Dekodierung der Instruktion if operation == "inc": # Das Ausführen der Operation memory[operand] += 1 elif operation == 'print': print(memory[operand]) else: raise RuntimeError("Invalid Opcode") # Gebe den Zustand nach jedem Befehl aus # print("Zustand nach %s: %s" %(program[pc], memory)) # Inkrementieren des Programmzählers pc += 1 program = [ # (Operation, Speicherzelle) ("inc", 0), ("inc", 0), ("inc", 1), ("print", 0) ] memory = [0] * 5 # 5 Worte an genulltem Speicher prozessor(memory, program)
Die gezeigte virtuelle Maschine beinhaltet beinahe alle Elemente, die zu unserem Verständnis von virtuellen Maschinen gehören.
Zum ersten haben wir den Prozessor (prozessor()), der die Semantik des Maschinenmodells als Interpreter implementiert; ein übergebenes Programm wird also direkt ausgeführt, anstatt ein Programm einer tieferen Ebene zu erzeugen.
Dieser Prozessor ist mit Hilfe der virtuellen Python-Maschine implementiert, die ihrerseits interpretiert wird.
Weiterhin hält program das auszuführende Programm und die Variable memory den Speicher der virtuellen Maschine.
Beides übergeben wir dem Prozessor, der die Befehlsfolge sequentiell ausführtNicht jede virtuelle Maschine hat eine solch sequentielle Ausführungsreihenfolge. Für manche Maschinenmodelle darf der Prozessor eine gute Reihenfolge, in gewissen Grenzen, selbst auswählen. Spielen Sie mit der virtuellen Maschine herum: (1) Lassen Sie sich den Zustand nach jedem Befehl ausgeben. (2) Fügen Sie einen neuen Befehl mul10 ein, der eine Speicherzelle mit 10 multipliziert. (3) Was passiert, wenn Sie einen Befehl in das Programm einfügen, der nicht vom Prozessor unterstützt wird? (4) Was passiert, wenn Sie die adressierte Speicherzelle beim print auf 100 setzen?
Das einzige, was in dem Beispiel fehlt, ist die Sprache der virtuellen Maschine, denn diese ist nur im Skript, und hoffentlich jetzt auch in Ihren Köpfen, zu finden.
Kurz könnte man sagen:
Ein Programm unserer Beispielsprache ist eine Liste von Befehlen, die jeweils aus Operation und Operand bestehen; dabei muss die Operation eine der Zeichenketten "inc" oder "print" sein.
Der Operand ist die Adresse einer Speicherzelle, von denen wir 5 haben, kodiert als Ganzzahl.
Mithilfe dieser Sprachdefinition können Sie nun noch einmal an die Aufgaben 3 und 4 herangehen und werden sehen, dass das Einfügen eines invaliden Befehls zwar Vordergründig zu einem RuntimeError geführt hat, aber der Prozessor eigentlich richtig gehandelt hat.
Denn das übergebene Programm war leider kein Program, welches gegen unser Maschinenmodell programmiert wurde, es hatte nur Ähnlichkeit mit einem validen Programm. Ähnlich verhält es sich mit der zu großen Speicheradresse (4); auch dort war das übergebene Programm nicht von unserer Sprachdefinition abgedeckt.
Die Sprache eines Maschinenmodells beschreibt also wie valide Programme für dieses Modell aussehen müssen, damit sie von einem Prozessor der Sprache verarbeitet werden können. Dabei kann eine Sprache alle validen Programme exemplarisch aufzählen, aber einfacher ist es, ein Regelwerk aufzustellen, gegen das man Programme prüfen kann. Um eine möglichst präzise Prüfung vornehmen zu können, ist es sinnvoll, diese Regel formal aufzuschreiben. Zum Beispiel, indem man ein weiteres Programm schreibt, welches die Regel kodiert. Im Folgenden führen wir genau das für unsere kleine Sprache durch. Führen Sie das Beispiel aus, und korrigieren Sie alle Fehler im Programm.
def sprache(program): for (operation, operand) in program: if operation not in ("inc", "print"): raise RuntimeError("Invalide Operation: " + str(operation)) if operand < 0 or operand > 5: raise RuntimeError("Invalider Operand: " + str(operand)) print("Valides Programm") programm = [ ("inc", 10), ("prnt", 3) ] sprache(programm)
Der hier gezeigte Code ist eine formale Beschreibung unserer Sprache, die gleichzeitig als Validierer arbeitet:
Wirft die Funktion eine Exception, so ist das übergebene Programm nicht Teil unserer Sprache.
Die Funktion sprache() könnte so wie sie hier steht auch Teil eines Übersetzers sein.
Dieser wird auch zuerst prüfen, ob das übergebene Programm von den Sprachregeln abgedeckt ist, bevor das Programm in die Sprache einer anderen virtuellen oder realen Maschine übersetzt wird.
Auf den Folien finden Sie weitere Beispiele für reale bzw. virtuelle Maschinenmodelle (RISC-V und C).









Wir haben gelernt, dass ein Übersetzer von der Sprache eines Maschinenmodells in die Sprache eines anderen Maschinenmodells übersetzt.
Zum Beispiel übersetzt gcc von der C-Sprache in die RISC-V-Sprache.
Dabei ist es zwar klassisch, dass die Richtung der Übersetzung immer von den oberen Schichten des Ebenenmodells zu den weiter unten liegenden geht, aber es ist nicht zwingend.
Genauso ist es möglich, dass ein Übersetzer von RISC-V-Assembler nach C (umgekehrte Richtung) übersetzt oder von C nach JavaScript (quer zum Ebenenmodell).
Jedoch stellt sich die Frage, wann wir von einem korrekten Übersetzer bzw. einer korrekten Übersetzung eines Programms sprechen können. Es ist natürlich notwendig, dass ein Übersetzer für jedes valide Quellprogramm, die er durch seine Validierungsfunktion vorher überprüft, ein ebenfalls valides Zielprogramm erzeugt. Diese notwendige Bedingung ist allerdings ganz sicher nicht hinreichend, da ein Übersetzer, der immer dasselbe Programm ausgibt, egal mit was wir ihm füttern, ganz sicher nicht nützlich ist.
Daher müssen wir noch einmal zu unserem Maschinenmodell zurückkehren und schauen, was wir vom Übersetzer erwarten. Wir möchten, dass ein Übersetzer ein Zielprogramm erzeugt, das sich so verhält, wie das Quellprogramm es getan hätte. Im einfachsten Fall bedeutet das, dass beide Programme die gleiche Ausgabe erzeugen, wenn sie mit den gleichen Eingabedaten ausgeführt werden. Meistens stellt das Maschinenmodell aber noch weitere Regeln für eine korrekte Übersetzung auf.
Bei dieser erweiterten Definition von korrekter Übersetzung erwarten wir nicht nur, dass das Zielprogramm das gleiche Ergebnis berechnet und uns mitteilt, sondern auch, dass es dies auf die gleiche Weise tut. Das Zielprogramm soll, im Grunde, die gleichen Schritte durchführen wie das Quellprogramm, nur auf einer anderen virtuellen Maschine. Um dies formaler zu fassen, führen wir auf den Folien den Begriff des beobachtbaren Zustands ein.
Wichtig beim Begriff des beobachtbaren Zustands ist, dass es vom Maschinenmodell bestimmt wird und es nicht zwingend den gesamten Speicher der virtuellen Maschine umfassen muss. Im Grunde legt das Maschinenmodell fest, welcher Teil des Zustandes wichtig ist und als beobachtbar gilt. Zum Beispiel legt die Programmiersprache C fest, dass die Werte von globalen Variablen beobachtbar sind. Der Hintergrund dieser Entscheidung ist, dass andere Threads die geschriebenen Werte von globalen Variablen sehen, wenn die Zuweisung ausgeführt wurde und nicht erst am Ende der Funktion, oder gar noch später.
Eine andere wichtige Erkenntnis aus der Definition der korrekter Übersetzungen ist das nur der beobachtbare Zustand erhalten werden muss.
Alles was die Sprache als nicht beobachtbar deklariert, kann vom Übersetzer beliebig verändert werden.
Zum Beispiel entfernen C-Übersetzer lokale Variablen aus Funktionen, wenn diese niemals verwendet werden.
Dies ist laut C-Standard eine legale Optimierung, da die Werte von lokalen Variablen nicht beobachtbar sind.
Umso mehr ein Maschinenmodell als nicht beobachtbar deklariert, umso leichter fällt es einem optimierenden Übersetzer ein effizientes Zielprogramm zu erzeugen.
Auf den Folien ist das Beispiel mit dem Kobold gezeigt, um genau dies zu verdeutlichen.
Für die Funktion foo() ist es unerheblich, wie die Funktionalität implementiert ist, da nur ihre Ausgabe von uns beobachtbar ist.
Wir können sie also ebenso mittels eines Kobolds implementieren anstatt mit einer Maschine aus Silizium und Strom.
5 Bootstrapping und Portierung











Wir haben bereits gesehen, dass Übersetzer Programme von einer Sprache, unter Beibehaltung der beobachtbaren Zustände, in eine andere Sprache transformieren. Bisher haben wir allerdings noch nicht darüber gesprochen, auf welcher Maschine dieser Übersetzer ausgeführt werden soll und wer das Übersetzerprogramm erstellt.
Aus Anwendersicht möchten wir einen Übersetzer für unsere Programmiersprache L haben, der auf der selben Maschine M läuft, auf der wir später auch das Zielprogramm ausführen wollen. Allerdings ist es sehr aufwendig einen Übersetzer direkt in M zu schreiben, denn M hat traditionellerweise weniger nützliche Abstraktionen als L (Ebenenmodell). Einen Übersetzer in Assembler zu schreiben macht einfach keine Freude. Außerdem wäre dann unser mühsam erstellter Übersetzer spezifisch für unsere Zielplattform und wir müssten mit jeder neuen Prozessorarchitektur einen neuen Übersetzer erstellen. Daher wollen wir lieber den Übersetzer in der Sprache L schreiben.
Dies hat auch den Vorteil, dass wir, als neue Sprachentwickler, gleich die Vor- und Nachteile unserer neuen Sprache kennenlernen und vielleicht noch Anpassungen an der Sprache vornehmen. Außerdem ist ein Übersetzer ein hinreichend komplexes Softwareprojekt, um herauszufinden, ob der Übersetzer korrekt arbeitet, wenn man ihn mit sich selbst füttert. Weil man sich in diesem Prozess quasi selbst an den Haaren aus dem Sumpf zieht, heißt dieser Prozess Bootstrapping (im Englischen zieht sich Münchhausen an den Schnürsenkeln, und nicht an den Haaren, aus dem Sumpf). Außerdem gehört es quasi zum guten Ton eines Sprachentwicklers, wenn sein Übersetzer in der eigenen Sprache geschrieben ist und sich selbst übersetzen kannWikipedia: Self-Hosting Compiler.
Prinzipiell haben wir zwei Möglichkeiten, die beide ihre Vor- und Nachteile haben. Zum einen können wir, neben dem Übersetzer für L, der in L geschrieben ist, auch einen Interpreter für L in M schreiben. Da ein Interpreter, zumindest wenn man erlaubt, dass er langsam sein darf, weniger Komplex ist als ein Übersetzer, spart man bei der Entwicklung und der Portierung auf neue Plattformen Zeit. Nachteil an dieser Variante ist, dass der Interpreter, wenn wir ihn nicht an anderer Stelle noch einmal verwenden können, Wegwerfware ist. Viel schwerwiegender ist allerdings das Problem der Konsistenz. Denn woher wissen wir, dass Interpreter und Übersetzer wirklich die gleiche Sprache implementieren oder ob sich doch in einem von beiden ein Fehler eingeschlichen hat.
Die andere Möglichkeit verwendet einen iterativen Prozess der Selbstübersetzung einer vereinfachten Variante des Übersetzers.
Nachdem man den Übersetzer (L->M) in L geschrieben hat, definiert man die Untermengen L' und M', die gerade noch so mächtig sind, um einen vollständigen Übersetzer zu schreiben.
Dies kann passieren, indem man exotische Sprachfeatures aus L weglässt bzw. die komplexeren Maschinenbefehle, die M eigentlich bietet, ignoriert.
Mit diesen Untermengen leitet man aus dem eigentlichen Übersetzer einen vereinfachten Übersetzer her, der in L' implementiert ist und nur ineffizienten Code für M' erzeugt.
Da M' eine Untermenge von M ist, läuft auch jedes Zielprogramm des vereinfachten Übersetzers auf unser eigentlichen Zielarchitektur.
Häufig kann die Ableitung des vereinfachten Übersetzers dadurch geschehen, dass man die komplizierteren Phasen des Übersetzungsvorgangs, wie Optimierung, einfach weglässt (z.B. mit #ifdef).
In einem zweiten Schritt müssen wir diesen vereinfachten Übersetzer per Hand, oder mit Hilfe eines anderen Übersetzers, für die Maschine M' implementieren.
Und obwohl unser vereinfachter Übersetzer eigentlich L übersetzen kann, können wir bei diesem manuellen Schritt sogar noch mehr Aspekte weg lassen, sodass am Ende nur ein Übersetzer für L'->M' entsteht.
Damit haben wir zum ersten Mal ein Programm, das auf der Maschine M läuft und so etwas ähnliches wie L übersetzen kann.
Im Folgenden übersetzen wir zuerst den vereinfachten Übersetzer mit seiner Implementierung. Damit bekommen wir eine volle Version des vereinfachten Übersetzers, der nun wirklich den gesamten Umfang von L versteht und verarbeiten kann. Als nächstes stecken wir den originalen Übersetzer in diesen vereinfachten Übersetzer und bekommen eine langsame Variante des originalen Übersetzers, der auf M' läuft, aber schon Code für M erzeugt. Eine weitere Iteration der Selbstübersetzung, liefert nun endlich das gewünschte Ergebnis: einen schnellen Übersetzer, der unsere Sprache L verarbeitet und Programme für M erzeugt. Zum Schluss wiederholt man den Vorgang ein weiteres Mal und vergleicht die Binärdateien der beiden letzten Übersetzer. Wenn alles geklappt hat, sind beide Dateien bis aufs letzte Bit gleich, was weiteres Vertrauen in die Übersetzungsleistung des entwickelten Übersetzers bringtEin interessantes Beispiel eines absichtlichen Fehlers beim Bootstrapping ist das klassische Paper von Ken Thompson, einem der Erfinder von C, Reflections on trusting trust. Dort hat Thompson einen Übersetzer geschrieben, der eine Hintertür beim Übersetzungsvorgang einbaut, wenn der Übersetzer selbst übersetzt wird..




Ein ähnliches Problem wie beim Bootstrappen tritt bei der Portierung eines Übersetzers auf eine neue Hardwarearchitektur auf. Allerdings ist hier der Vorgang deutlich vereinfacht, da wir bereits einen Übersetzer für L haben, der auf der alten Hardware läuft. Wir erweitern unseren Übersetzer dahingehend, dass er die neue Architektur N als Ausgabeformat unterstützt und übersetzen ihn für M. Eine zweite Iteration der Selbstübersetzung, liefert nun einen Übersetzer der auf N läuft und Code für N erzeugt.
Früher war die Portierung von Übersetzern ein größeres Problem, da ein Übersetzerprogramm meist nur ein einziges Ausgabeformat unterstützt hat.
Also entweder konnte er Code für M erzeugen oder für N.
Ein Beispiel für solch einen Übersetzer ist gcc; dort benötigt man für jede Zielplattform ein eigenes Übersetzerbinary.
Modernere Übersetzer sind Multi-Targetfähig und sind von Anfang an darauf vorbereitet, Code für unterschiedliche Architekturen zu erzeugen (siehe LLVM-Grafik weiter oben).
6 Zusammenfassung


Fußnoten:
Einen kurzen Überblick über LLVM-IR bietet der folgende Blogeintrag: https://idea.popcount.org/2013-07-24-ir-is-better-than-assembly/
Die Unterscheidung zwischen statisch (vor der Laufzeit) und dynamisch (zur Laufzeit) wird uns durch das ganze Semester hindurch begleiten. Es ist das erste Kernkonzept von Programmiersprachen, dem wir begegnen; man kann es als die Frage "Was passiert in einer Sprache statisch und was passiert dynamisch?" formulieren.
Nicht jede virtuelle Maschine hat eine solch sequentielle Ausführungsreihenfolge. Für manche Maschinenmodelle darf der Prozessor eine gute Reihenfolge, in gewissen Grenzen, selbst auswählen
Ein interessantes Beispiel eines absichtlichen Fehlers beim Bootstrapping ist das klassische Paper von Ken Thompson, einem der Erfinder von C, Reflections on trusting trust. Dort hat Thompson einen Übersetzer geschrieben, der eine Hintertür beim Übersetzungsvorgang einbaut, wenn der Übersetzer selbst übersetzt wird.

